Scaling Dataconstrained Language Models
Scaling Dataconstrained Language Models - Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. We run a large set of experiments varying the extent of data repetition and compute budget, ranging up to. Neurips 2023 · niklas muennighoff , alexander m. Nvidia teams up with google deepmind to drive large language model innovation. This paper studies the scaling behavior of language models by repeating the training data to multiple epochs. Extrapolating this trend suggests that training dataset.
Specifically, we run a large set of experiments varying the extent of data. This work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess. The authors extend the recent successful chinchilla. Niklas muennighoff · alexander rush · boaz barak · teven le scao · nouamane tazi · aleksandra piktus · sampo pyysalo ·. 5.6k views 6 months ago talks.
The current trend of scaling language models involves increasing both parameter count and training dataset size. Specifically, we run a large set of experiments varying the extent of data. The authors extend the recent successful chinchilla. The current trend of scaling language models involves increasing both parameter count and training dataset size. Extrapolating this trend suggests that training dataset.
Scaling DataConstrained Language Models DeepAI

Niklas muennighoff · alexander rush · boaz barak · teven le scao · nouamane tazi · aleksandra piktus · sampo pyysalo ·. Specifically, we run a large set of experiments varying the extent of data. Web in this study, researchers investigated how to scale up language models when there is limited data available. The current trend of scaling language models.
Scaling Laws For Neural Language Models Elias Z Wang Ai Researcher My

Model size (# parameters) training data (# tokens) training compute (flops) resources model size training data x = training compute palm (2022) 540b. We run a large set of experiments varying the extent of data repetition and compute budget, ranging up to. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing.
Emergent Abilities of Large Language Models

This work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess. In this paper, we propose. Web linearizing large language models. Rush , boaz barak , teven le scao , aleksandra piktus ,. Specifically, we run a large set of experiments varying the extent of data.
Two minutes NLP — Scaling Laws for Neural Language Models by Fabio

May 6, 2024, 11:41 am pdt. Rush , boaz barak , teven le scao , aleksandra piktus ,. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. How to scale a language model with a. Lstms were initially introduced in the early 1990s.
The best way to Keep Scaling Large Language Models when Data Runs Out

Web linearizing large language models. Rush , boaz barak , teven le scao , aleksandra piktus ,. By niklas muennighoff, et al. The current trend of scaling language models involves increasing both parameter count and training dataset size. Web by kanwal mehreen, kdnuggets technical editor & content specialist on may 13, 2024 in language models.
New Scaling Laws For Large Language Models Lesswrong Hot Sex Picture
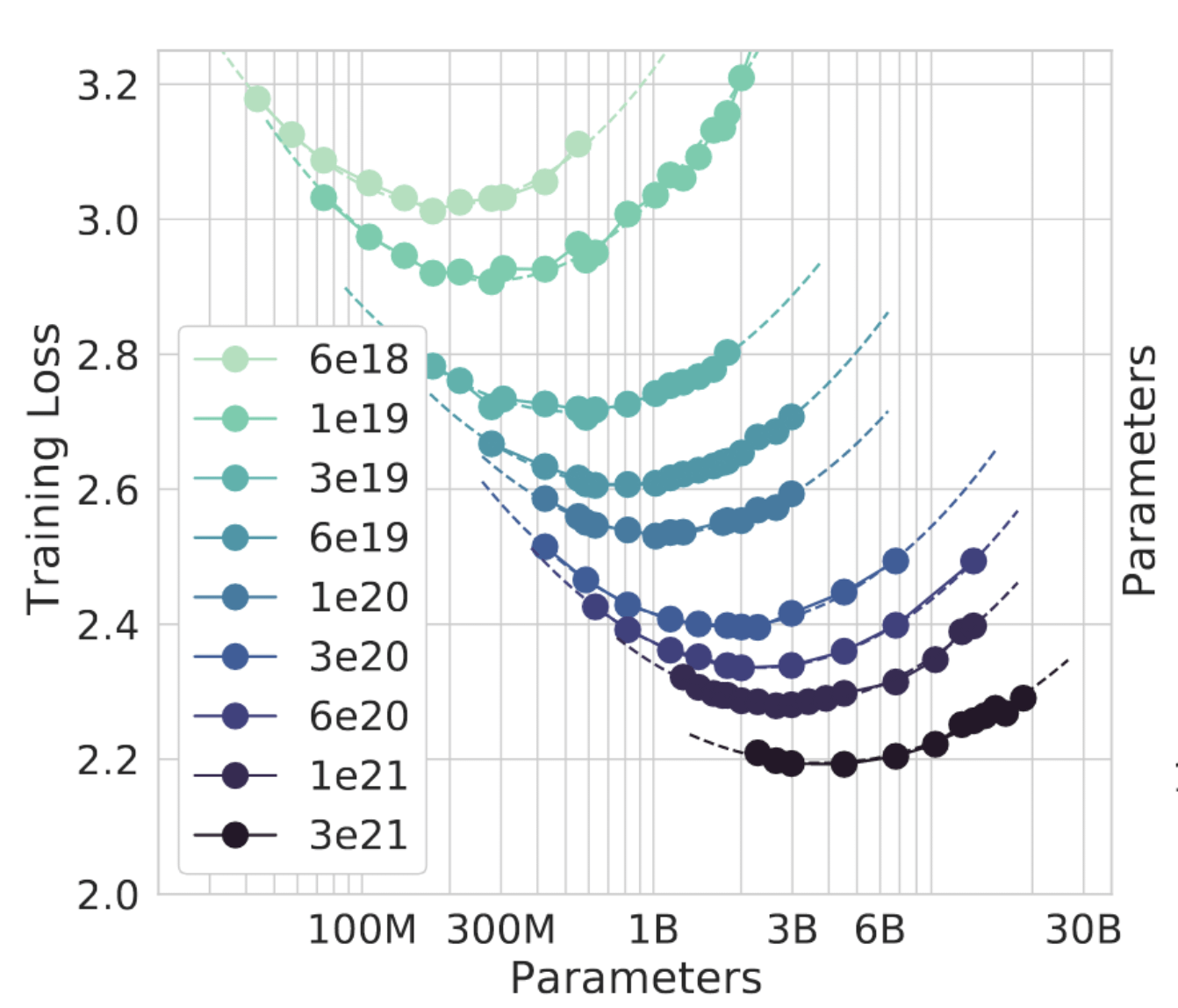
Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. Niklas muennighoff · alexander rush · boaz barak.
The AI Scaling Hypothesis

Extrapolating this trend suggests that training dataset. 5.6k views 6 months ago talks. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. In this paper, we propose. Paligemma, the latest google open model, debuts with nvidia nim.
Scaling laws for neural language models

This work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess. In this paper, we propose. Niklas muennighoff · alexander rush · boaz barak · teven le scao · nouamane tazi · aleksandra piktus · sampo pyysalo ·. May 6, 2024, 11:41 am pdt. By niklas muennighoff, et.
Scaling Hypothesis The path to Artificial General Intelligence?

Extrapolating this trend suggests that training dataset. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. Web linearizing large language models. 5.6k views 6 months ago talks. Extrapolating this trend suggests that training dataset.
Thoughts on the new scaling laws for large language models Severely

Web linearizing large language models. Web in this study, researchers investigated how to scale up language models when there is limited data available. By niklas muennighoff, et al. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. May 6, 2024, 11:41 am pdt.
Scaling Dataconstrained Language Models - Specifically, we run a large set of experiments varying the extent of data. The authors extend the recent successful chinchilla. Neurips 2023 · niklas muennighoff , alexander m. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. Web this limitation prevents us from fully exploiting the capabilities of protein language models for applications involving both proteins and small molecules. We run a large set of experiments varying the extent of data repetition and compute budget, ranging up to. Extrapolating scaling trends suggest that training dataset size for llms may soon be limited by the amount of text. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. 5.6k views 6 months ago talks. Rush , boaz barak , teven le scao , aleksandra piktus ,.
How to scale a language model with a. May 6, 2024, 11:41 am pdt. Rush , boaz barak , teven le scao , aleksandra piktus ,. In this paper, we propose. The current trend of scaling language models involves increasing both parameter count and training dataset size.
How to scale a language model with a. Extrapolating this trend suggests that training dataset. Web this limitation prevents us from fully exploiting the capabilities of protein language models for applications involving both proteins and small molecules. We run a large set of experiments varying the extent of data repetition and compute budget, ranging up to.
Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. 5.6k views 6 months ago talks.
How to scale a language model with a. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. They found that repeating data for multiple epochs can improve.
Extrapolating Scaling Trends Suggest That Training Dataset Size For Llms May Soon Be Limited By The Amount Of Text.
By niklas muennighoff, et al. We run a large set of experiments varying the extent of data repetition and compute budget, ranging up to. Paligemma, the latest google open model, debuts with nvidia nim. Rush , boaz barak , teven le scao , aleksandra piktus ,.
Lstms Were Initially Introduced In The Early 1990S.
Neurips 2023 · niklas muennighoff , alexander m. Nvidia teams up with google deepmind to drive large language model innovation. How to scale a language model with a. Specifically, we run a large set of experiments varying the extent of data.
Web This Work Proposes And Empirically Validate A Scaling Law For Compute Optimality That Accounts For The Decreasing Value Of Repeated Tokens And Excess Parameters And.
Niklas muennighoff · alexander rush · boaz barak · teven le scao · nouamane tazi · aleksandra piktus · sampo pyysalo ·. The authors extend the recent successful chinchilla. Web linearizing large language models. Web by kanwal mehreen, kdnuggets technical editor & content specialist on may 13, 2024 in language models.
The Current Trend Of Scaling Language Models Involves Increasing Both Parameter Count And Training Dataset Size.
They found that repeating data for multiple epochs can improve. Web this work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters and. This work proposes and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess. Model size (# parameters) training data (# tokens) training compute (flops) resources model size training data x = training compute palm (2022) 540b.